Kantenerkennung für die ImageHorizonlibrary
Welche Problem beim Einsatz der Bilderkennung mit der ImageHorizonLibrary entstehen können - und wie wir sie gelöst haben.
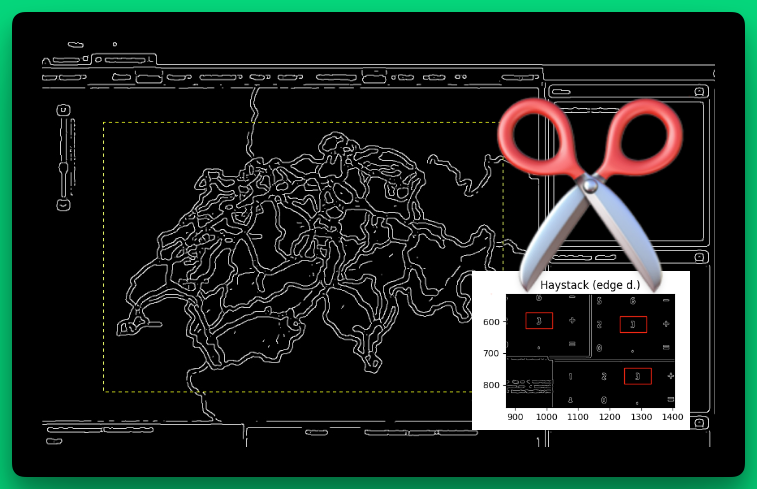
Edge Detection in der ImageHorizonLibrary - ein Experiment mit viel Potential.
(Hinweis: statt ImageHorizonLibrary verwende ich die Abkürzung IHL.)
TL’DR
- Der Bildpattern-basierte Ansatz zur UI-Automatisierung versucht, auf einem Screenshot des aktuellen Desktops einen bestimmten Teilbereich zu finden. Auf die Region des erkannten Bereichs kann dann z.B. mit der Maus geklickt werden.
- Bereits 1 abweichender Pixel lässt die Methode mit den Standardeinstellungen allerdings fehlschlagen.
- Libraries wie IHL erlauben kleinere Pixel-Abweichungen, indem sie einen prozentualen Toleranzwert entgegennehmen (
confidence,tolerance,similarity…). - Problematisch bleiben die Unterschiede augenscheinlich identischer Bilder, bei denen eine große Masse der Pixel um minimale Details abweicht.
- Kantenerkennung (“Canny edge detection”) ist ein probates Mittel, um aus Bildern nur noch die Linien zu extrahieren, welche hohe Kontrastübergänge beschreiben.
- Ein Pull Request von Gautam Ilango und mir ergänzt die ImageHorizonLibrary um diese Methode als zusätzliche Strategie.
Basics: So funktioniert die Bilderkennung
Die für Robot Framework geschriebene Library ImageHorizon arbeitet auf Basis des Python-Moduls PyAutoGUI. Mit diesem Modul können Maus und Tastatur auf Linux, Mac und Windows automatisiert gesteuert werden. Dank der IHL kann diese Technologie in Robot-Tests eingesetzt werden, zum Beispiel für End2End-Monitoring mit Robotmk.
Damit die Library weiß, wohin sie den Mauszeiger führen soll (z.B. um einen Klick auszuführen), muss ihr die Zielregion vorher bekannt sein. Diese sucht sie anhand eines sogenannten Referenzbildes.
Nehmen wir als Beispiel dieses Dialogfeld:
Um den Button “Nicht speichern” anklicken zu können, wird ein Referenzbild erstellt und unter dem Namen nicht_speichern.png im Testordner abgelegt:
An der Stelle im Test, wo die Abfrage erwartet wird, kommt das IHL-Keyword Click Image (Link) zum Einsatz: als Argument wird lediglich der Name der Referenzdatei nicht_speichern angegeben:
Click Image nicht_speichern
Im Keyword Click Image passiert nun folgendes:
- Erstellen eines Screenshots vom aktuellen Bildschirm ("Haystack" = Heuhaufen)
- Laden des Referenzbildes ("Needle" = Nadel)
- Suchen der Nadel im Heuhaufen
Side note: Bilder werden in der Informatik dargestellt als eine Matrix aus Zahlen.
Diese Zahlen beschreiben die Intensität eines jeden Pixels im Gesamtbild. Im Gegensatz zu Graustufenbildern (1 Wert pro Pixel) sind RGB-Bilder eine Matrix aus 3 Werten pro Pixel.
Die “Suche” eines Referenzbildes im Gesamtbild besteht also aus der mathematischen Aufgabe, die Koordinate einer (Sub-)Matrix innerhalb einer anderen zu bestimmen.
Kleine Pixel-Abweichungen und die Lösung
Die oben beschriebene Vorgehensweise funktioniert so lange, wie die Needle-Matrix exakt im Haystack vorhanden ist.
Tanzt auch nur ein RGB-Wert (z.B. (233,40,22)) aus der Reihe (z.B. (233,41,22)), so liefert die Suche nach dem Needle-Bild ein leeres Ergebnis. Game Over. Test FAILED.
“Abweichung…? Moment mal - entweder eine Applikation läuft oder sie läuft nicht. Wie soll es denn zur Abweichung einzelner Pixel kommen?”
Auf den ersten Blick scheint das Szenario von Pixel-Abweichungen konstruiert: man möchte gerne glauben, dass Haystack-Bilder 100% vorhersehbar sind. Hier die zwei Hauptgründe, warum man sich darauf nicht verlassen sollte:
- Bildkompression: Nicht selten werden beim End2End-Monitoring die Applikationen über Citrix oder RDP getestet (z.B. um die Performance über WAN-Strecken zu messen). Der Administrator solcher Systeme kann eine Einstellung vorgeben (und macht das meistens auch!), die eine Einwahl auch über eine langsame Netzwerkverbindung erlaubt; der Einwahlserver kompensiert das, indem er die Bildinformation für den Client dynamisch herunterrechnet. Die dabei entstehenden Artefakte im Bild stören zwar keinen Endanwender, bringen aber den End2End-Test zu Fall.
- Schriftglättung (Font-Antialiasing): Schriftarten sind vektorbasiert, Computerdisplays aber rasterbasiert. Anti-Aliasing ist vereinfacht gesagt das, was der Computer unternehmen kann, wenn eine darzustellende Schriftlinie nicht exakt in das Raster der Bildschirms passt. Er errechnet dann weitere Pixel in Zwischentönen, sodass die Schrift für das menschliche Auge “weich” aussieht und leichter zu lesen ist.
Siehe Wikipedia:

- Bonus-Grund Nr. 3: Fremd-Quellen. Dazu später mehr (Praxisbeispiel).
Mit diesen Problemen hatten wohl auch schon die Autoren der ImageHorizonLibrary, Eficode, zu tun; jedenfalls beinhaltet die IHL die Möglichkeit, einen Wert namens confidence zu setzen (Keyword: Set Confidence). confidence ist ein Wert zwischen 0 und 0.99 und beschreibt, wieviel Prozent des Referenzbildes (Needle) im Suchbild (Haystack) enthalten sein müssen - oder anders ausgedrückt: wie viele Augen die Library bei der Bilderkennung zudrücken darf.
# Setzen von Confidence beim Import der Library
Library ImageHorizonLibrary confidence=0.95
# Alternativ: Ändern von Confidence während des Tests
Set Confidence 0.95
confidenceist ein Feature, welches die Installation des Python-Modulspython-opencverfordert.
confidence: Praxisbeispiel
Das folgende Bild zeigt den Buchstaben “a” in einem Bild mit den Abmessungen 10x10px:

Lass uns annehmen, dass dieser Buchstabe auf dem Desktop erkannt werden soll und dieses Bild nun als Referenzbild (Needle) verwendet wird.
Die Erkennung wird zu 100% funktionieren.
Wir schalten nun die Schriftartglättung des Betriebssystems ein. Sie fügt der Darstellung des Buchstabens plötzlich weitere “künstliche” Pixel hinzu (es sind ca. 20):

Unser Test schlägt nun fehl.
Wir haben einen üblen Verdacht: Schriftartglättung! Also drehen wir am confidence-Wert und setzen diesen auf 0.9 herunter. Jetzt müssen nur noch 90% des Needle-Bildes übereinstimmen.
Der Test schlägt immer noch fehl.
Wir setzen confidence auf 0.8 herab und siehe da - IHL erkennt den Buchstaben wieder. Die im folgenden Bild gelb markierten Pixel sind die, welche IHL beim Bildvergleich als nicht mit der Region im Originalbild übereinstimmend erkannt hat. Das sind 19 Pixel von 100 und damit sind wir gerade noch unter der Toleranz von 20%:

Confidence: ein Zwischenfazit
Wenn man sich mit dem confidence-Level langsam nach unten tastet, kann man geringe Pixelabweichungen abfangen.
Stelle sicher, dass die Systeme, auf denen Du Tests ausführst, nach ganz strikten Regeln eingerichtet sind.
Dazu gehören Punkte wie die oben erklärte Schriftglättung, aber auch die Auflösung (Stichwort: responsive UI), Bildschirmschoner, etc.
Die Gefahr massiver Pixelabweichungen
Die bisher gezeigten Beispiele wurden allesamt mit dem mit dem auf pyautogui basierenden Bilderkennungs-Modus von IHL durchgeführt. Damit konnte ich aufzeigen, dass man sich hier und da mit einer Anpassung der confidence helfen kann, um “kleinere” Pixel-Abweichungen in den Griff zu bekommen.
Wie sieht es denn mit größeren Abweichungen aus?
Noch größere Abweichungen? So etwas kommt doch nicht vor!
Doch. Das kommt vor.
Warum confidence alleine scheitert
Greifen wir das Beispiel vom vorherigen Abschnitt auf und nehmen an, dass der Buchstabe auch dann erkannt werden soll, wenn sich die Hintergrundfarbe geändert hat. Das ist z.B. der Fall beim “Hover”-Effekt eines Buttons, wenn man die Maus darüber bewegt. (Im Übrigen kann dieser Fehler in Web-Tests mit Selenium oder Playwright nicht vorkommen!)
Wieder in Gelb dargestellt: die Pixel, die nicht mit dem Referenzbild übereinstimmen:

Dieses Bild (oben) stimmt zu über 3/4 nicht mehr mit dem Originalbild (unten) überein. Nur noch 23% der Pixel entsprechen dem Original.
Rein rechnerisch funktioniert auch ein confidence-Wert von 0.2 mit einem so kleinen Haystack-Bild wie in diesem Beispiel.
In der Praxis jedoch ist der Haystack ein ganzer Bildschirm, in dem es Dutzende solcher “20%"-Übereinstimmungen geben kann.
Praxisbeispiel (dreh wirklich jeden Stein um…)
Diesen Fall möchte ich gerne mit einem Beispiel aus einem Kundenprojekt untermauern. Und dieses Beispiel zeigt wieder einmal, dass man nichts als gegeben hinnehmen sollte.
Ich hatte mit Robotmk einen End2End-Test für eine Autobahn-Management-Software implementiert.
In der Integrationsphase fiel auf, dass von dem Robot-Test, der das Laden der Landes-Autobahnkarte mit IHL überprüfen sollte, ca. 3-5% der Ausführungen fehlschlugen. Die Fehlermeldung war: Image not found.
Kann doch nicht sein, denkt man sich und prüft gewissenhaft die Logs. Es sah alles gut aus.
Und natürlich fummelte ich an der confidence. :-) Aber ohne Feedback, was genau IHL erkennt, war das totaler Blindflug. Die Ergebnisse wurden nur noch schlechter.
Im Rahmen meiner Fehlersuche erweiterte ich daraufhin den Test, sodass er unmittelbar vor der Erkennung partial Screenshots (ein cooles Feature der Screencap Library) von exakt der zu erkennenden Kartenregion anlegte.
Hier zwei solcher Bilder der Landeskarte:
- das Referenzbild
- den zugeschnittenen Teil des Screenshots
und sie scheinen - auch bei extremer Vergrößerung - absolut gleich auszusehen (oder nicht?):
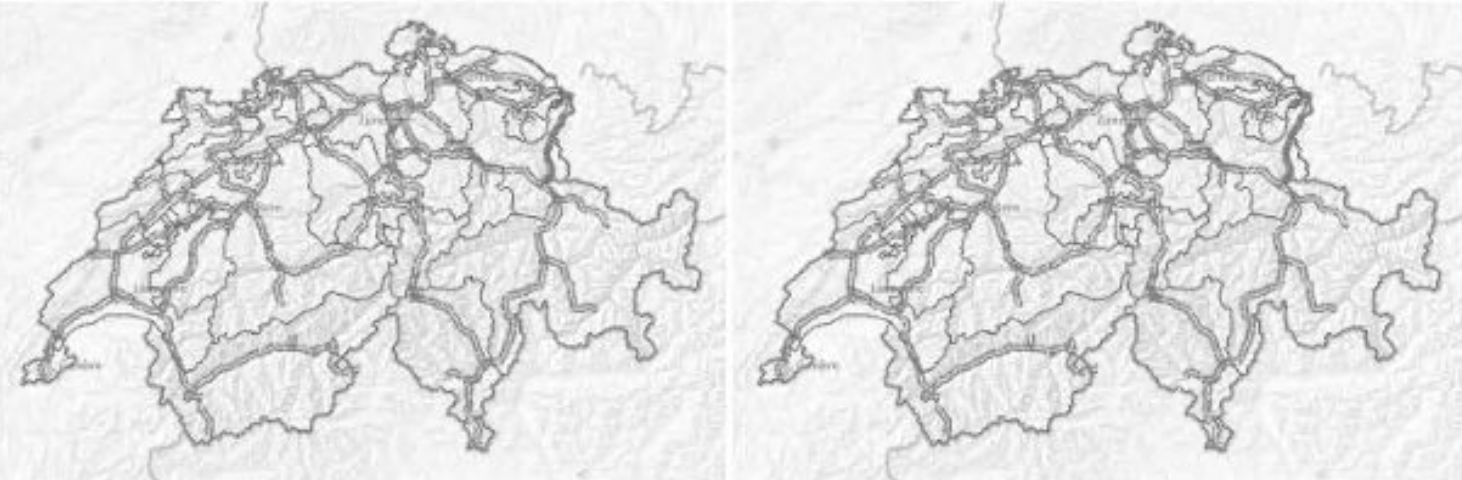
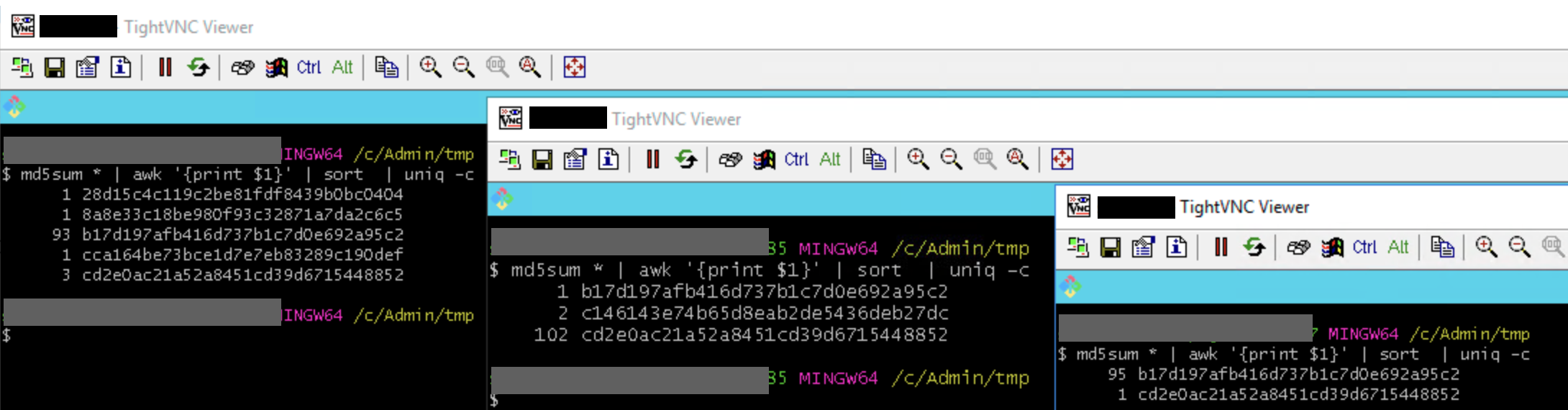
Nach einiger Zeit verglich ich dann die MD5-Prüfsummen der angelegten Screenshots von den Maps, wie sie tatsächlich angezeigt wurden.
Ich staunte nicht schlecht: Wie erwartet waren die meisten Prüfsummen gleich (das Referenzbild passte also), ein kleiner Teil der Prüfsummen aber war auf den drei Testhosts tatsächlich stets unterschiedlich! (Seht euch die MD5-Hashes mal genau an: b17 und cd2 sind komplementär Ausreißer und Haupt-Hash!)
(Natürlich wünscht man sich in so einem Fall drei frisch aufgesetzte Test-Maschinen. Aber das Leben ist kein Ponyhof: neue VMs hätten Wochen gedauert…)
Ich lud dann je ein Haupt-Bild und ein “Ausreißer”-Bild in ein Online-Tool für Bildvergleiche hoch.
Ein und dieselbe Karte. Zwei Bilder. (Damit keine Missverständnisse auftreten: die roten Pixel sind die Unterschiede… )
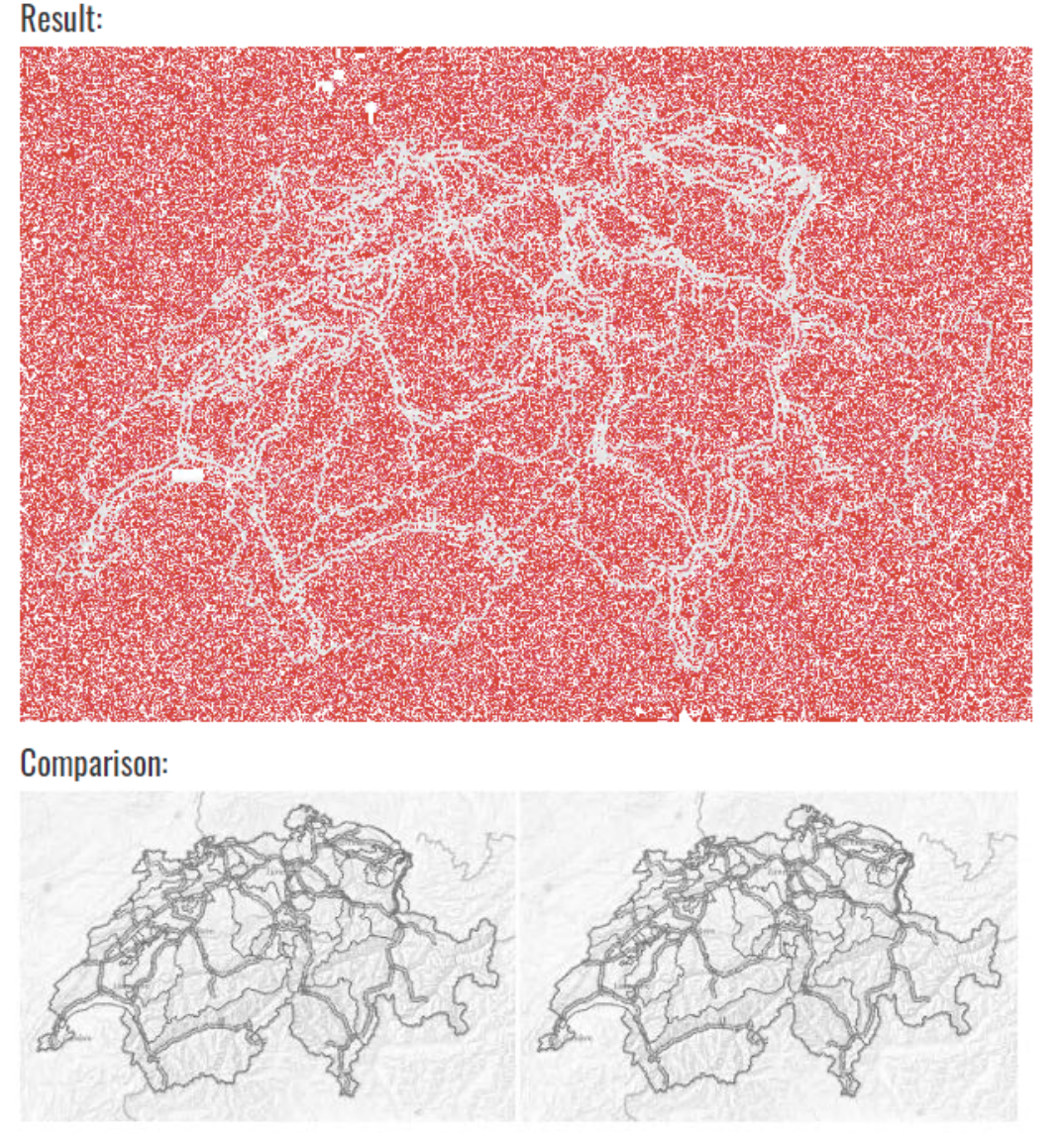
Ja, die Maps werden vereinzelt tatsächlich unterschiedlich vom Map-Provider geladen. Bei starker Vergrößerung sieht man an bestimmten Stellen eine minimale Veränderung der Helligkeit.
Ich darf sagen, dass ich an diesem Ergebnis zu knabbern hatte: wie kann ein und derselbe Kartenausschnitt auf drei Testmaschinen in 3-5% der Fälle so unterschiedlich geladen werden? (Die Antwort werde ich vermutlich nie erfahren. Für mich war es ein wichtiges Learning, beim Debugging wirklich jeden Stein umzudrehen…)
Kantenerkennung to the rescue
Die zündende Idee kam vom Kollegen Frank Striegel (NOSER Engineering AG, CH): Needle und Haystack müssen vor dem Bildvergleich jeweils von solchem “Grundrauschen” (woher auch immer es kommt) bereinigt werden.
Aus seinem Protypen heraus entwickelte ich ein custom Keyword, welches mit Hilfe des skimage-Frameworks für Python beide Bilder vorab mit Kantenerkennung verarbeitet und die daraus resultierenden Bilder zum Vergleich heranzieht. Es funktionierte.
Erweiterung der ImageHorizon-Library mit skimage
Vorweg: Die Idee, eine komplett neue Library zu schreiben, war schnell vom Tisch. Die ImageHorizonLibrary ist eine hervorragende Library für RobotFramework, die ich allein wegen ihres Unterbaus (Pyautogui, das war’s) schätze. Zum Vergleich: die SikuliXLibrary für Robot Framework erfordert Java (!) und einen “JRobot Remote Server” (!!) zu Übersetzung der Python-Keywords in Java-Kommandos.
Zusammen mit Franks Kollege Gautam (ebenfalls NOSER AG) habe ich in den letzten Wochen intensiv an einer Erweiterung der ImageHorizonLibrary programmiert, welche die Möglichkeit bietet, Kantenerkennung in End2End-Tests einzusetzen. Wir sind kurz davor, den Pullrequest an Eficode zu stellen und auch mächtig gespannt, ob er angenommen wird. :-)
Kantenerkennung in a nutshell
Wie Edge detection genau funktioniert, ist vielfach im Netz beschrieben. Der von uns eingesetzte “Canny-Algorithmus” (entwickelt von John Francis Canny, 1986, ganz hervorragend dokumentiert hier) unterteilt sich in diese fünf Schritte:
- Gaußscher Weichzeichner, um Rauschen und Unreinheiten zu reduzieren. Der
sigma-Parameter bestimmt die Stärke des Filters. - Sobel’sche Kantenerkennung: Bestimmung des Helligkeitsverlaufes in x- und y-Richtung; Bestimmung der Peaks durch Ableitung
- non-max-suppression: garantiert 1px breite Kanten durch Entfernen von nicht relevanten Pixeln
- Double threshold: Klassifizierung von Kanten-Pixeln in strong, weak und low candidates
- Hysterese: Entfernung von weak candidates, bzw. Zuteilung zu benachbarten candidates.
Wie sich der sigma-Parameter von Schritt 1 auf die final erkannten Kanten auswirkt, ist anschaulich dargestellt auf Wikipedia:

Die Strategie “edge”
Die von uns erweiterte IHL ist voll kompatibel zur bestehenden Version. Ich habe unter Anwendung des Strategy-Design-Patterns dafür gesorgt, dass der Eingriff in den Code so minimal wie möglich erfolgt.
Das bedeutet, dass sich in der Handhabung der Library nichts ändert. Ohne weitere Parametrisierung arbeitet sie nach wie vor mit der Bilderkennung per pyautogui:
Library ImageHorizonLibrary reference_folder=...
Nun angenommen, ein Needle-Bild wird wegen zu starker Abweichungen nicht zuverlässig im Haystack gefunden. Dann (und wirklich nur dann!) gibt es einen guten Grund, zur Bilderkennung die Kantenerkennung hinzuzuziehen. Das Keyword Set Strategy erlaubt es, die Strategie während des Tests zu setzen:
Set Strategy edge
Alle bestehenden Keywords der IHL arbeiten ab diesem Moment mit der Bilderkennung auf Basis der edge detection. Referenz- und Screenshot-Bild werden vor dem Bildvergleich also erst per Kantenerkennung auf das Wesentliche reduziert.
In bestimmten Situationen kann es vorkommen, dass das Referenzbild selbst nach der Kantenerkennung nicht zuverlässig auf dem Screenshot gefunden werden kann (z.B. weil Artefakte bei der Bildkompression durch RDP/Citrix einen minimal anderen Kantenverlauf ergeben haben).
Solche Pixelabweichungen bewegen sich im vom Grundrauschen bereinigten Bild aber immer im Bereich der Kanten, zählen also zur relevanten Bildinformation. Es reicht somit, confidence ggf. leicht herabzusetzen (z.b. auf 0.9), um eine verlässliche Bilderkennung zu erreichen.
Der Image Debugger
Bliebe es beim bisher Vorgestellten, so besäße die IHL nun eine weitere Erkennungsstrategie, die zwar “irgendwie besser” arbeitet, deren Arbeitsweise aber ebenfalls nicht nachvollziehbar ist.
Damit in beiden Strategien die confidence und in skimage auch noch weitere Parameter feinjustiert werden können, wurde ein neues Keyword Debug Image geschaffen. Es kann direkt vor der Stelle im Test eingesetzt werden, wo ein Referenzbild nicht zuverlässig funktionieren will.
Debug Image
Click Image image_varying
Nach einem Neustart der Robot-Suite wird der Test nun an exakt der problematischen Stelle anhalten und die ImageHorizon-Debugger-GUI öffnen, welche Gautam Ilango entwickelt hat.
Von hier aus wählt man das Needle-Bild aus dem reference_folder:
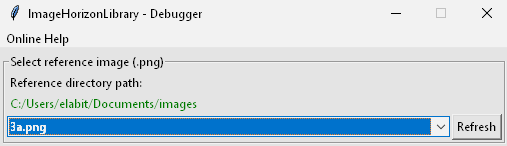
Darunter teilt sich die Ansicht in zwei Bereiche für die beiden Erkenungsstrategien “Default” und “Edge” mit verschiedenen Slidern zur jeweiligen Parametrisierungund je einem Button Detect reference image:
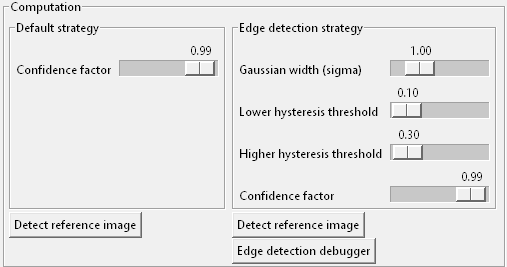
Klickt man diesen, so versucht der Debugger, das Referenzbild mit der entsprechenden Strategie auf dem Desktop zu finden - auf exakt die Weise wie bei Ausführung eines Robot-Keywords (z.B. Wait For).
Der Viewer im unteren Bereich zeigt daraufhin das Needle-image und links davon, rot markiert, alle auf dem Desktop gefundenen Treffer.
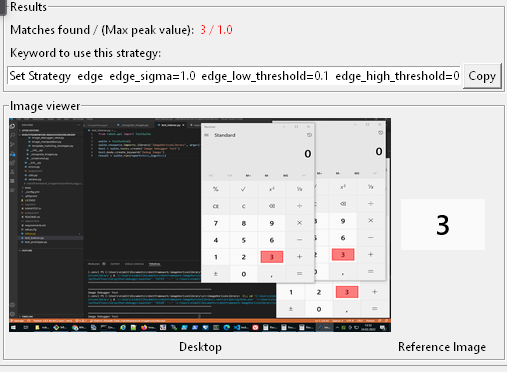
Der Image Debugger liefert hier zwei wichtige Informationen:
- Wie viele Treffer wurden insgesamt gefunden? - Bisher tappte man hier mehr oder weniger um Dunklen. Bei mehreren (gleichen) Treffern greift die Library nämlich zum ersten im Array aller erkannten Regions - ohne weitere Warnung.
Anhand “Matches found” kann man entscheiden, ob man sich besser ein eindeutiges Referenzbild als “Fixpunkt” suchen und von dort aus mit relativen Keywords zum gewünschten Punkt gehen sollte (z.b. mit
Click To The Right Of). - Wie ist die Erkennungsqualität? - Bisher war die Einstellung der
confidencenur aufwändig per “try & error” (Bild matcht/matcht nicht) möglich. Der “Max. Peak Value” zeigt an, zu wie viel Prozent das Referenzbild im besten Match übereinstimmt. Das erleichtert die Feinjustierung derconfidenceerheblich.
Ist die optimale Einstellung gefunden, kann das Keyword Set Strategy zur Parametrisierung der Strategie per copy/paste in das Robot-File übertragen werden.
So richtig interessant wird die Sache, wenn man nach Ausführung der Kantenerkennung den Button “Edge detection debugger” klickt: er öffnet ein weiteres Fenster, in dem man Needle- und Haystack-Bild vor und nach der Kantenerkennung sehen kann. Die erkannten Bereiche können mit der Lupe herangezoomt und bewertet werden:
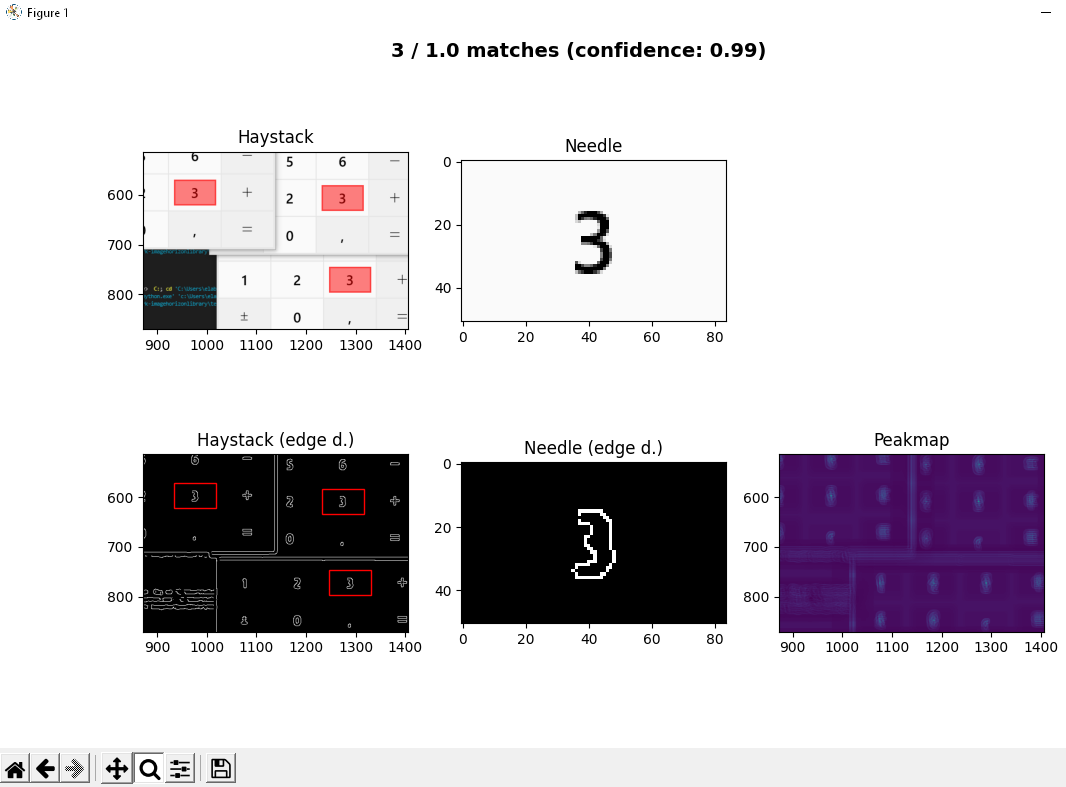
confidence (und im Fall von skimage auch sigma, low_threshold und high_threshold) können dank visueller Kontrolle über den Debugger nun so justiert werden, dass möglichst nur ein Treffer erzielt wird.
Als “Treffer” zählen nur die Regionen mit einer Pixel-Übereinstimmung höher als die
confidence. Auch wenn während des Debuggens mehrere Treffer sichtbar sind, so wird während der Ausführung immer die Koordinate der Region zurückgegeben, welche die höchste Übereinstimmung aufweist.
Zusammenfassung
Unsere Erweiterung der ImageHorizonLibrary durch Kantenerkennung ermöglicht das Testen von Applikationen auch dann, wenn das Haystack-Bild durch Bildkompression, Schriftglättung o.ä. “optimiert” bzw. “verfälscht” wurde (das liegt im Auge des Betrachters…), oder gar durch dynamisch nachgeladene Inhalte nicht 100% vorhersehbar ist - wie am Bespiel der Autobahn-Operator-Software zu sehen.
Apropos, so sieht übrigens die Karte der Schweiz nach der Kantenerkennung aus (die gelbe Linie zeigt die Abmessungen des Referenzbildes):
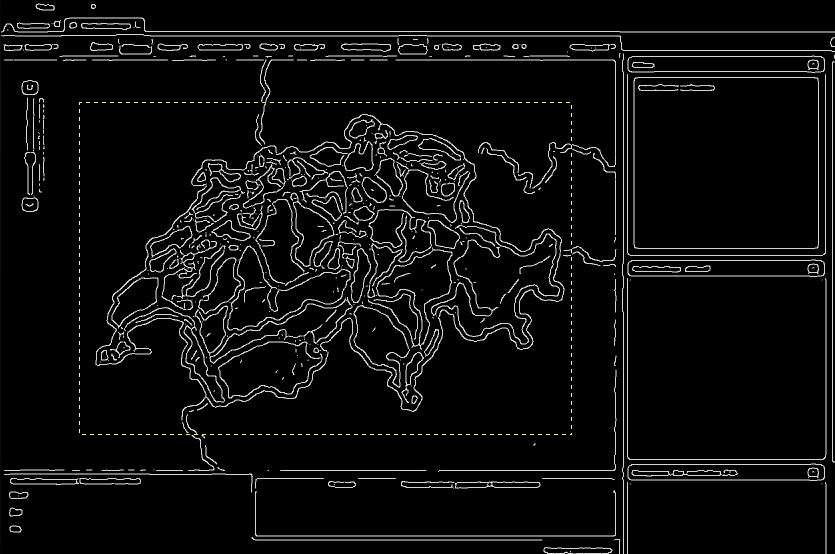
Gautam und ich sind sehr stolz auf diese Weiterentwicklung, die wir Eficode nun in Form eines Pullrequests auf Github vorgelegt haben.
Updates
2022-05
Der Pullrequest ist aktuell noch nicht akzeptiert. Wenn Du die Erweiterung der ImageHorizonLibrary schon einmal testen möchtest, gehe wie folgt vor:
# --- create a new virtual environment
virtualenv .venv
# on Linux
. .venv/bin/activate
# on Windows
.venv/Scripts/activate
# --- install RF
pip install robotframework
# --- clone the repository, switch branch
git clone [email protected]:simonmeggle/robotframework-imagehorizonlibrary.git
cd robotframework-imagehorizonlibrary
git fetch -a
git checkout skimage
# --- install the current development state as "editable" module
pip install -e .
2023-02
Ich durfte meine Erfahrungen auf der Robocon 2023 im Rahmen eines Techtalks präsentieren:
Gegen Ende des Videos erkläre ich auch den aktuellen Stand der Dinge: leider war Eficode bis heute nicht bereit, die Library an einen anderen Maintainer zu übergeben - trotz der vielen offenen Issues und der fehlenden Zeit zur Wartung und Weiterentwicklung (wie sie selbst zugaben).
Einen Fork mit einer dauerhaften Abhängigkeit zur Codebasis von Eficode halte ich für eine sehr schlechte Idee. Es steht die Idee im Raum, die Library komplett neu zu schreiben unter Berücksichtigung dieser Punkte:
- Fixen offener Bugs
- Hinzufügen längst überfälliger Keywords
- Implementieren der Kantenerkennungs-Strategie